无
”python爬虫 js网页 4步“ 的搜索结果
爬取网页的时候,爬取不到源码,显示Javascript is required. Please enable javascript before you are allowed to see this page.去论坛里搜索了问题,发现好像只有我一个人有这个问题下面是我的代码// 请把代码...
Python爬虫是一种使用Python编程语言来自动化获取网页数据的技术。这项技术主要涉及到向目标服务器发送请求,获取HTML页面内容,然后通过解析HTML来提取所需的数据。Python爬虫在数据收集、网络监测、自动化测试等...
爬取网页的时候,爬取不到源码,显示Javascript is required. Please enable javascript before you are allowed to see this page.去论坛里搜索了问题,发现好像只有我一个人有这个问题下面是我的代码// 请把代码...
曾尝试各种方法,没有效果。使用的是函数requests.get(),已写header、cookie、User-Agent,也写了rsp.encoding = rsp.apparent_encoding。 但是仍是爬取不了。奇怪的同一个网站同一个榜单,只是页数不同,前若干页...
今天,来讲讲如何用python爬去数据用js动态加载的网页。 所用到的库selenium以及与它搭配的webdriver,用来打开浏览器,从网页中读取数据的过程,这样才能找到数据。 代码如下: from selenium import webdriver ...

对于这种js加密+动态网站+反调试的网站,这也算是一个行之有效的思路。
广告关闭腾讯云11.11云上盛惠 ,精选热门产品助力上云,云服务器首年88元起,买的越多返的越多,最高返5000元!location.href = localstorage.getitem(url) || :toast(e.msg || 登录出错) }) }) : toast(e.msg) }) }...

用python的爬虫爬取数据真的很简单,只要掌握这六步就好,也不复杂。以前还以为爬虫很难,结果一上手,从初学到把东西爬下来,一个小时都不到就解决了。
笔者编写的搜索引擎爬虫在爬取页面时遇到了网页被重定向的情况,所谓重定向(Redirect)就是通过各种方法(本文提到的为3种)将各种网络请求重新转到其它位置(URL)。每个网站主页是网站资源的入口,当重定向发生在...
请注意,这只是一个简单的示例,实际爬取过程中可能需要处理各种情况,例如处理JavaScript生成的内容、处理网页的编码问题、处理爬虫的频率限制等等。或者,如果你想爬取的是特定格式的图片(例如JPEG或PNG),你...
Python-Python3爬虫实战JS加解密逆向教程
开发环境:win10-64 python2.7.16 chrome77from selenium import webdriverdriver = webdriver.Chrome(executable_path='chromedriver.exe')driver.get('http://全部加载完成超级慢的网站')user = 'abc'pwd = '123...
最新版的python爬虫知识,其中还介绍了Android开发的基础知识。 目录: 网络协议&爬虫简介;爬虫请求模块;正则表达式;xpath;Beautiful Soup库;selenium;多线程;Scrapy框架;CrawSpider使用和settings文件讲解...
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。基本上主流的和经典的都有,这里我就不放...
使用python的scrapy框架,对某动态购物网站使用js生成的动态数据进行抓取,并且可以存储到数据库或者excel或者csv文件中。
在着手写爬虫抓取网页之前,要先把其需要的知识线路理清楚。 首先:了解相关的Http协议知识; 其次:熟悉Urllib、Requests库; 再者:开发工具的掌握 PyCharm、Fiddler; 最后:网页爬取案例;

「Python爬虫」如何在Python 中执行JavaScript呢?全民python2019-09-02 01:13:07阅读(478)(0)> 在使用爬虫中,经常会遇到网页请求数据是经过 JS 处理的,特别是模拟登录时可能有加密请求。而目前绝大部分前端 JS ...
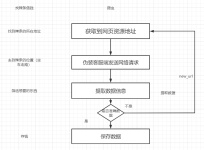
有很多页面,当我们用request发送请求,返回的内容...另外一种就是js动态加载得到的数据,然后放入页面中。这两种情况下,对于用户利用浏览器访问时,都不会发现有什么异常,会迅速的得到完整页面。其实我们之前学过...
网页常常会因为网络原因,程序问题等等导致打开网页慢,一直在那里打圈圈。出现这种情况时网页里的很多元素就没有加载完成,如果你刚好要定位的元素没有加载完,这时定位的话程序就会抛出异常。所以程序里要加入等待...

主要介绍了Python3实现抓取javascript动态生成的html网页功能,结合实例形式分析了Python3使用selenium库针对javascript动态生成的HTML网页元素进行抓取的相关操作技巧,需要的朋友可以参考下
JS逆向是一种分析反爬机制的行为,通过分析反爬机制如何加密、混淆和模拟JS代码的执行,使之能够成功处理并渲染网页。由于JS逆向的方式需要进行复制粘贴,因此开发过程中需要耗费一定的时间和精力。在Python上,我们...
目标网站:http://beijing.chineseoffice.com.cn/Template/office_complete.html当查看网页源码时,没有各楼信息,实际写在JS里,包括翻页功能。Chrome的developer tool查看网络包信息: 上代码:url = ...
推荐文章
- YOLOv7如何提高目标检测的速度和精度,基于优化算法提高目标检测速度-程序员宅基地
- linux中进程退出函数:exit()和_exit()的区别_linux结束进程可以用哪些函数,它们之间有何区别?-程序员宅基地
- sqlserver55555_sqlserver把小数点后面多余的0去掉-程序员宅基地
- Angular6 和 RXJS6 的一些改动_angular6,requestoptions改成了什么-程序员宅基地
- C++解析XML文件_c++ xml解析-程序员宅基地
- R语言使用caret包的train函数构建多元自适应回归样条(MARS)模型构建分类模型、trainControl函数设置交叉验证参数、自定义调优评估指标_多元自适应回归样条 r-程序员宅基地
- Android ListView控件显示数据库中图片_安卓获取listview里的图片并显示-程序员宅基地
- python123程序改错题库,2016最新二级C语言考试题库及答案(程序改错专项练习 精华版)...-程序员宅基地
- Roser S.Pressman在UMLChina交流实录-程序员宅基地
- 【Linux】shell编程1(shell脚本书写格式、脚本中的环境变量、普通变量、自定义环境变量、变量数组、位置变量、状态变量、内置变量、变量扩展)_linux脚本格式-程序员宅基地